虚拟机4-运行时数据区
聊完了类加载器,也就是我们的 JVM 输入端,下面我们开始一个新话题,聊聊JVM中的运行时数据区是什么。咱们先回顾一下Java虚拟机的组成。
# 运行时数据区
大家知道,类加载子系统负责加载字节码,但这些信息加载后得有个地方存吧?这就引出了运行时数据区——JVM专门开辟的一块内存,用来保存类信息和程序运行时产生的数据。运行时数据区分两大块:线程私有区和线程共享区。线程私有区有三个部分:程序计数器、虚拟机栈和本地方法栈。线程共享区也有三个:堆、方法区,还有方法区里的运行时常量池。其中细节,待我娓娓道来。
先说线程私有区。程序计数器就像个“进度条”,记录每个线程执行到哪儿了,因为Java程序靠线程运行,每个线程都有自己的计数器。虚拟机栈是私有区核心,保存方法调用和运行时数据,比如你调用一个方法,它的数据就压到栈里,执行完再弹出来。本地方法栈跟虚拟机栈很像,但它是为本地方法服务的,比如Java调用操作系统功能时用到的数据就存在这儿。
再说线程共享区。堆是咱们最熟悉的地方,主要存对象,程序跑起来后new出来的东西基本都在这儿。方法区存的是类的“原始定义”, 也就是创建对象实例所需的模板,比如方法、字段这些元数据。顺带提一嘴“元数据”,类的元数据通常指描述类结构和行为的信息,这是元数据的一些经典定义。方法区里还有个运行时常量池,专门放常量,比如用static final定义的那种,后面讲到时再细说。
总结一下,运行时数据区是JVM内存的关键,线程私有区管执行过程;共享区管共享数据。最重要的两块是虚拟机栈和堆。
# 私有区域
# 程序计数器
这是运行时数据区里最简单的一个组件——程序计数器。顾名思义,它就是记录程序执行位置的计数器。
首先,Java代码编译成字节码后,是一条条指令,比如“bipush”“putstatic”之类的。程序计数器干啥呢?简单说,它告诉你当前线程下一条要执行的字节码是第几行,比如“第3行”“第5行”。每个线程都有自己的计数器,线程私有,互不干扰。
它有几个特点。
**程序计数器:存储的是当前线程下一条将要执行的字节码指令在方法区中的地址索引。**在线程切换时,程序计数器能够记住当前线程执行到了哪条指令,以便下次恢复执行时能够从正确的位置继续。
执行Java方法时,计数器有值,指向下一条指令的行号。但如果跑的是native本地方法,计数器就空了。为什么?因为Java方法在JVM管辖下,JVM知道每一步在干啥,可native方法是调用操作系统或C语言库,JVM管不着,执行位置没法追踪,所以计数器没值。
因为只有一行数据,占内存极小,所以不会溢出,不会出现“Out of Memory”错误。
程序计数器 (PC) 与 返回地址的协作
当一个方法被调用时(无论是普通 Java 方法还是 native 方法),JVM 在虚拟机栈中创建一个新的栈帧。
当前程序计数器的值(调用者的下一条指令地址)被 ➔➔➔保存到➔➔➔ 新栈帧中的返回地址中。
程序计数器更新为新方法的起始指令地址,开始执行新方法。
为啥要有计数器?直接从上到下跑不就行了?这里得说说Java的线程特性。Java程序靠多线程运行,假设有4个线程,但CPU只有一个核心,怎么办?操作系统会用时间片轮流处理。比如,时间片1跑线程1,时间片2跑线程2,CPU快速切换,看着像并行,其实是串行。切换时,计数器就派上用场了——它记住线程跑到了哪一行,下次轮到这个线程时接着跑,不会乱。比如线程1跑完第1行,计数器指向第2行,切换回来就从第2行开始。
再回头说native方法。JVM管不了C语言的内存,Java和C的运行环境是隔离的,所以调用native时,JVM不知道执行到哪,计数器就空着。这其实是因为我们执行 native 的时候,实际上是在执行它的机器码。而机器码并不是直接由我们的运行时数据区去管理的,所以他没有正确的指向。
总结一下:程序计数器记录线程下一条字节码的行号,每个线程独有,跑Java方法时有值,跑native时为空,内存占用小,不会溢出。它的核心作用就是在线程切换时,确保程序位置不丢(给方法返回值打下手的)。
# 虚拟机栈
虚拟机栈——主要用来保存方法调用时产生的数据和嵌套调用的信息。
先说说啥是栈。栈是计算机里的一种数据结构,像堆集装箱那样:紧密排列,先进后出。放进去叫入栈,取出来叫出栈。集装箱先放的最底下,后放的在上头,取时只能从上面一个个拿走,这就是栈的特点,大学课本里有一个图就很形象,每调用一个方法,我们就新开辟一个方法栈。
虚拟机栈在JVM里干啥呢?它保存方法调用的执行上下文。每次线程跑起来,虚拟机栈就创建,线程结束它就销毁。
那么栈里存啥?局部变量、操作数、返回信息这些,线程私有的。一个方法调用,就往栈里压一块数据,叫“栈帧”。栈帧就像一块子执行流程,每块对应一个方法。
举个例子。假设有个main方法,里面调用method1,method1又调用method2。线程启动时,main方法入栈,生一个栈帧。调用method1,又压一个栈帧,里面存method1的局部变量。接着method2入栈,再压一个栈帧,存它自己的变量。这时栈顶是method2,栈底是main。方法执行完就出栈:method2完了先出栈,退到method1;method1完了再出栈,退到main;main完了,栈空,线程销毁。
总结一下:最底下的栈帧叫栈底,最上面的叫栈顶,也就是当前帧。虚拟机栈是线程私有的,存方法调用数据,用栈帧表示。方法执行时入栈,完了就出栈,和线程生命周期一致。线程活着时栈存在,线程死了栈就没了,因为线程结束的前提是栈已经清空。
# 虚拟机栈的空间
这一节的关注点在于如何合理设置虚拟机栈的空间?
前面讲过,虚拟机栈是线程私有的,存方法调用数据,每调用一个方法就压一个栈帧。
虚拟机栈有四个特点:一是线程私有,栈帧互不干扰;二是存当前方法执行状态,运行时不垃圾回收;三是生命周期跟线程一致,方法调用入栈,结束出栈,栈空了线程就销毁;四是栈深度有限,取决于空间大小。
OOM 问题
栈空间默认咋样呢?Java 1.5后,每个栈默认1M,之前是256K。一般1M够用,但不能设太大。为啥?每个线程占1M,高并发时服务器内存吃不消,因为在高并发场景下,如果每个线程的虚拟机栈设置得过大,最直接的后果是导致 JVM 整体的内存消耗过高,当 JVM 无法申请到足够的内存来创建新的线程或者整体内存超出限制时,就会抛出 OutOfMemoryError。
怎么调呢?用参数-Xss,后面加数值和单位,比如-Xss512k就是512K。日常开发,方法嵌套不多、局部变量少,512K就行。
栈空间大小决定最大深度。栈帧存局部变量等数据,占内存。所有栈帧,也就是栈桶里面的总内存不能超-Xss设的值。栈帧大小不固定,深度就动态变化。但空间不够咋办?有俩错误:一是StackOverflowError,固定空间用满抛出,比如设512K,塞不下就溢出,一般出现在循环调用的情况下;二是OutOfMemoryError,动态扩展时内存不够抛出。不过动态扩展不推荐,为啥?死循环能占满所有内存,拖垮其他程序。
栈空间大小怎么玩
首先,我们看看怎么设置固定的栈长度呢?就由这个例子来说明吧。假设在 main 里调用 test,test 自己无限递归调用,没有出口,肯定会栈溢出。默认情况下,跑一段时间后会溢出。为啥?因为每次调用 test,栈都会压入一个栈帧,栈空间有限,当栈帧数量达到一定深度时,默认的栈内存就用满了。
想让它跑得更久怎么办?可以设置一个更大的栈空间,比如增大栈内存到某个较大的值,这时能支持的递归深度会显著增加,说明栈空间变大了。但如果设得太大,比如远超实际需求,就有点夸张了,不建议真这么用。换个适中的值,设个适中的栈大小,溢出的深度会比默认多一些,但又不会太离谱,这样更合理。(咱们可以设置小一点,我这里主要是不想让他占用太多的 Heap 空间)
还有个关键点,栈帧的大小跟方法里的局部变量有关。比如我们在做菜,锅的大小是固定的,之前放的是红豆,体积小,能装很多颗;现在改放土豆,土豆比红豆大,能装的数量就变少了。程序里也一样,如果我在 test 里多加几个局部变量,或者加个大数组,每个栈帧占的空间就变大,能容纳的总深度自然减少。所以,如果方法里有较多局部变量或大数组,得权衡栈空间设置是否够用,具体还得看业务场景。
总结:设栈空间用-Xss加数值,比如-Xss512k。固定长度为主,别动态扩展!!!
# 栈帧
今天咱们聊聊“栈帧的组成”,这是虚拟机运行的核心。简单说,一个栈帧对应一个方法,方法嵌套调用就像栈帧层层堆叠,撑起整个虚拟机运行。每个栈帧里都有啥?四部分:局部变量表、操作数栈、动态连接和返回地址。这四部分里,局部变量表和操作数栈最关键,知识点多,后续会重点讲。动态连接偏理论,返回地址偏实用。
- 局部变量表,内存占用最大,存方法里的局部变量。
- 操作数栈,保存执行过程中的中间结果,用“先进后出”的栈结构处理,很直观。
- 动态连接,稍微复杂点,把字节码里的符号引用转成直接引用。
- 返回地址,方法嵌套时,执行完return要跳回调用它的方法,这地址就存了调用方法的程序计数器值。
Tips: 其实咱们写代码跟日常生活也没啥区别,下面我用一个故事,把这些几个关键的部分串联起来,
把栈帧想象成一次旅行打包,每次开辟一个新的栈帧,就好像盗梦空间里面我进入了新的梦境要进行一次特别行动:
- 局部变量表:你的“行李箱”,装旅途中要用的东西(局部变量),最占空间。
- 操作数栈:你的“随身背包”,路上临时放点零食、水(中间结果),用完就拿走。
- 动态连接:你的“导航仪”,把地图上的地名(符号引用)变成具体路线(直接引用)。
- 返回地址:你的“回程车票”,旅行完得知道回哪儿(调用方法的地址)。
# 局部变量表
局部变量表是栈帧四大数据区之一,主要负责存方法执行时的局部变量信息。
首先,局部变量表是栈帧里最重要的一部分,负责存方法的参数和局部变量。它在代码编译时就确定长度,方法调用时创建,退出时销毁。简单说,它是线程私有的,存的是方法运行时的“临时变量”。局部变量表的主要功能是为方法提供一个私有的、结构化的、高效的变量存储空间,让方法能在运行时正确访问参数和局部变量,同时通过 slot 和重用机制优化内存使用。它是栈帧的“心脏”,因为方法的所有逻辑都离不开它存的数据。局部变量表是栈顿最主要的存储空间,决定了栈的深度。
slot 变量槽
那什么是 slot 变量槽呢?它就是局部变量表里存储变量的最小单位。32位的数据,比如 int、float 或引用类型,占 1 个 slot;64位的数据,比如 long 或 double,占 2 个 slot。比如,一个方法里有 int a、long b、double c,局部变量表可能是这样:slot 0 放 a,slot 1 和 2 放 b,slot 3 和 4 放 c。规则很清晰。
重点来了,slot 还有个特性叫“槽重用”。啥意思?就是空闲的槽可以被新变量复用,节省空间。比如,一个方法里定义了 int a,后面有个 if 块里定义了 int b,b 用完就销毁了,槽空出来。接着定义 int c,执行引擎一看二号槽空着,就把 c 塞进去。这样,局部变量表最多可能就用 2 个槽,而不是 3 个。这就是槽重用的妙处。再看个细节:在实例方法和构造方法里,slot 0 默认是 this,指向当前对象;但静态方法没 this,所以 slot 0 就直接存参数了。比如 main 方法,slot 0 是参数 args,不是 this。
slot 生命周期
那怎么知道槽啥时候创建、啥时候销毁呢?字节码里有个局部变量表,静态记录了每个变量的“出生点”和“寿命”。start_pc 是起始行号,length 是作用范围。比如 start_pc 是 8,length 是 4,变量就从第 8 行活到第 11 行,过期就清槽,留给别人用。运行时,执行引擎根据这规则动态分配。这个跟操作系统的设计思想也很像,其实它的作用范围是用偏移量来计算的,也就是 length = offset。
总结一下:局部变量表存参数和变量,用 slot 单位,32 位占 1 个,64 位占 2 个;槽能重用,节省空间;实例方法 slot 0 是 this,静态方法没有;start_pc 和 length 管变量生命周期。明白这些,你就搞懂了局部变量表的核心。
# 操作数栈
“操作数栈”其实很简单,就是一个“先进后出”的数据结构,像弹夹一样,只能从上面放进去(入栈),或者拿出来(出栈)。
那在Java里,它有啥用呢?一句话概括:操作数栈是字节码指令执行时,中间计算结果的临时存储空间。
听起来有点抽象?在刚刚的想象例子里面,这就是我们去进行频繁操作的随身背包。咱们直接用例子说明白。
假设有个简单方法:int i = 10, j = 18, k = i + j,最后返回k。这代码在Java虚拟机里怎么跑呢?咱们得看字节码。字节码是静态存着的指令,运行时由执行引擎一行行加载,配合操作数栈完成计算。过程是这样的:
- 先把10入栈,栈顶就是10。
- 出栈,把10存到局部变量表,变成变量
i。 - 再把18入栈,栈顶变成18。
- 出栈,存到局部变量表,变成
j。 - 把
i(10)和j(18)再入栈,栈里从下到上是10、18。 - 执行加法指令,栈顶两个数相加,变成28,存回栈顶。
- 出栈,把28存到局部变量表,变成
k。 - 最后把
k入栈再出栈,作为返回值。
看到没?操作数栈就是个中转站,计算中间结果全靠它。加法简单,但复杂运算也一样,靠入栈、出栈搞定。因为它在内存里跑,结构简单,效率特别高。
栈深度计算
再看个复杂点的例子。如果用double或long类型,比如double a = 10.0, long b = 18,它们是64位数据,一个值占两个栈深度。局部变量表里也是占两个槽位。字节码里,比如先把10.0入栈,占两个深度,再把18入栈,又占两个深度,栈深度就到4了。面试时常问:这段代码操作数栈最大深度是多少?你得算清楚每个数据的深度。
这里总结一下线程的操作数栈的两个要点
- 操作数栈是计算时的临时存储空间,靠入栈出栈完成计算任务。
long和double占两个栈深度,算最大深度时别漏了。
# 动态连接和方法返回地址
动态链接
先说动态连接。啥是动态连接?简单讲,就是把字节码里写死的符号引用,变成运行时内存里的直接引用。听起来抽象,咱们看个例子。假设有个程序,从main方法开始,依次调用s1、s2、s3、s4,形成一个调用链。编译成字节码后,这些方法咋存的呢?打开字节码文件,你会看到方法名不是直接写死的,而是指向常量池里的某个位置,比如s1对应常量池#26,里面存着方法名和描述。这种字面上的关联,叫符号引用。
程序运行时,JVM加载字节码,把这些信息塞进方法区的运行时常量池,变成二进制数据。这时,每个栈帧里有个指针,叫动态连接,指向常量池里对应方法的内存地址。比如运行到s1,栈帧里的动态连接就指向s1的内存位置,告诉JVM:“我现在执行这个方法。” 后面s2、s3、s4也是类似。
为啥不把方法数据直接塞栈帧里?因为栈帧空间有限,方法数据放常量池,通过指针引用,能省空间、提效率。这就是动态连接的意义:从字节码的符号引用,变成内存的直接引用。
返回地址
再说方法返回地址。这个好理解,就是方法执行完后,告诉程序接下来跳哪儿。还是刚才的例子:main调用s1,s1调用s2,一路到s4。s4执行完后,没写return也得退出,对吧?退出后跳回s3的下一行,s3完了跳s2,最后回到main,程序结束。这跳转靠啥?靠方法返回地址。它存的是调用者的程序计数器值,也就是下一条指令的位置。比如s4完了,栈帧出栈,返回地址指向s3的下一条指令,程序就接着跑。
动态连接管方法定位,返回地址管跳转顺序。栈帧的四部分——局部变量表、操作数栈、动态连接、返回地址。核心就是动态连接让方法调用高效,返回地址保证跳转正确。
# 本地方法栈
先说啥是本地方法。Java里有些方法前面加了native关键字,比如public native void hello();,一看就没实现体。这不是接口那种抽象方法,而是Java用来调用其他语言(比如C语言)功能的一种方式。比如屏幕上的例子,我们用System.loadLibrary("helloNative")加载一个C写的DLL库,然后定义个native方法去调用DLL里的同名功能。实现呢?不在Java里,而在DLL里。
本地方法有仨特点:第一,它是Java调用非Java代码的接口;第二,定义时没实现体,代码在DLL或Linux的SO文件里;第三,为啥有它?因为Java是应用层语言,搞底层操作(像驱动)得靠操作系统提供的功能。不过现在Java越来越强,很多原来靠native的事,它自己就能干了,所以native用得越来越少。加上它依赖本地环境,影响Java的可移植性,能不用就不用。
那本地方法栈是干啥的?前面咱们了解到了虚拟机栈,存的是Java方法的调用。本地方法栈长得像它,但存的是native方法的调用。比如有个Java方法s2调用native方法s3,本地方法栈里就生成一个栈帧,指向C语言的实现。区别在哪儿?虚拟机栈跑Java代码,本地方法栈跑非Java代码。
这调用咋实现的?靠本地方法接口。它是JVM的一个组件,作用像中介,把Java的请求传给操作系统,执行DLL里的功能,再把结果返回来。比如s2调s3,本地方法接口把数据扔到C的运行空间,C执行完再返回。因为Java和C的内存是隔离的,Java管不了C的细节,控制力很弱,所以不到万不得已,别碰native。
本地方法栈还有俩特点
- JVM规范没强制规定它咋实现,只要是栈的“先进后出”就行,用数组还是别的结构,随厂商发挥。
- 有的JVM压根不分本地方法栈和虚拟机栈,比如HotSpot,直接合二为一。
本地方法栈存native方法调用,通过本地方法接口桥接Java和底层功能。但它不常用,控制难、可移植性差,日常开发能避就避。
# 共享区域
# Heap
堆是干啥的?一句话:存对象实例。你程序里new出来的对象,基本都放堆里。JVM一启动,堆就创建,内存也分配好,是线程共享区,所有线程都能访问里面的对象数据。堆有个特点:物理上分散,逻辑上连续。啥意思?内存条是由多个颗粒组成的,堆数据可能散落在不同颗粒上,但JVM通过地址映射,让我们用起来像一块完整的空间。面试常问:堆内存是连续的还是分散的?答:物理分散,逻辑连续。
因为堆是共享的,高并发时多个线程同时操作同一个对象,就会冲突。为了解决这问题,堆里有个线程私有的缓冲区,叫TLAB(Thread Local Allocation Buffer)。每个线程有自己的一小块内存,操作对象时先放自己那儿,互不干扰,提高并发效率。
再说堆和引用类型的关系。看个例子:void test() { B b = new B(); }。运行时,虚拟机栈里有个栈帧,局部变量b存着啥?一个指针,指向堆里new B()创建的对象实例。引用类型本质就是指针,存的是堆中对象的地址。方法结束,栈帧没了,b也没了,堆里的对象就没引用了,变成“可回收”状态。但它不会立刻被清理,只有JVM觉得内存不够,触发垃圾回收(GC)时才清。为啥不立刻回收?效率考虑。频繁GC会拖慢程序,所以JVM攒到一定条件再统一清理。
总结堆的特性:
- 堆是JVM核心内存区,存对象实例;
- JVM启动时创建,线程共享;
- 物理分散,逻辑连续;
- 有TLAB提高并发效率;
- 对象靠引用关联,GC时清理。代码里
new一下,对象就进堆,引用没了就等GC。
# 堆的结构和对象分布
堆分两大块:新生代和老年代。新生代存新创建的对象,不太稳定,随时可能被垃圾回收(GC)。老年代存经过多次GC还活着的对象,相对稳定,GC不频繁。新生代又细分成三块:Eden(伊甸园)和两个Survivor(幸存者0区和1区)。
简单记:新生代管新对象,频繁GC;老年代管老对象,稳定少GC。
顺带提一句,JDK 1.8后还有个元空间(Metaspace)位于方法区里,存类的元数据,比如类和方法的描述信息,几乎不被GC清理。堆管对象实例,元空间管类模板信息,别混了。
堆大小配置。堆大小靠俩参数设置:-Xms是初始堆大小(新生代+老年代),JVM启动就分配;-Xmx是最大堆大小,满了就抛OOM(内存溢出)。默认值呢?不设的话,初始是物理内存的1/64,最大是1/4。比如我16G内存,默认初始约256M,最大约4G。运行程序,Runtime.getRuntime().totalMemory()显示初始245M,maxMemory()显示最大3627M,比理论值略小,因为系统和JVM预留了点内存。
堆内比例咋分的?新生代占1/3,老年代占2/3,固定不变。咋验证?加个参数-XX:+PrintGCDetails,跑程序看GC日志。新生代76M,老年代175M,加起来251M,和初始堆245M差不多,比例也符合1:2。日志里还能看到Eden、Survivor的具体占用,老年代用了多少。
实际工作中咋设堆大小?用-Xms1g -Xmx1024m这样,手动指定初始1G、最大1G(单位M和G等价)。跑一下,初始和最大都显示981M,略低于1G,因为JVM有预留。好处是啥?初始和最大设一样,程序运行时不用频繁调整内存,提高效率。但缺点是启动就占1G,其他程序用不了,所以得算准大小。
咋算合适的大小?有个建议:-Xms和-Xmx设为老年代Full GC后存活对象3-4倍的空间。Full GC啥意思?我们可以简单理解为老年代一次大清理。假设清理后剩1G对象,那就设3-4G。线上跑一跑,看实际存活多少,乘以3或4就行。
总结:
- 堆分新生代(1/3,含Eden和Survivor)和老年代(2/3),存对象实例;元空间存类元数据。
- 设堆用
-Xms和-Xmx,建议相等,值为老年代存活对象的3-4倍。记牢这些,都是经验所谈。
# 堆对象分配过程
先回顾堆结构。JDK 1.8后,堆分新生代和老年代。新生代存新对象,不稳定,GC频繁;老年代存稳定对象,GC少。新生代又分三块:Eden(伊甸园)和两个Survivor(S0和S1),内存比例默认8:1:1。比如新生代1G,Eden占800M,S0和S1各100M。为啥Eden占大头?因为日常开发里,大多数新对象都先塞进Eden,GC也最频繁,得留够空间。
分贷回收机制、对象咋分配的?
- 第一次 GC,
new出来的对象先进Eden。Eden满了,JVM触发Minor GC(年轻代回收),用可达性分析看哪些对象没引用。没引用的清掉,有引用的标上年龄(Age=1),复制到S0。Eden清空,S0存活对象年龄1。 - 第二次Eden又满了,Minor GC扫描Eden、S0、S1,没引用的清掉,新存活的对象Age=1复制到S1,S0里的老对象Age加1变成2,也复制到S1,Eden和S0清空。这次S0是From区(源头),S1是To区(去向)。
- 第三次Eden满,Minor GC再来,新对象Age=1进S0,S1里老对象Age加1变2和3,也进S0。Eden和S1清空,S1成From,S0成To。From和To就这样轮换。
关键点:GC触发是Eden满,但回收范围是整个新生代(Eden+S0+S1),别以为只清Eden。对象Age每熬过一次GC加1,默认阈值15。Age超15,比如第15次GC后变成16,就进老年代,老年代GC少得多(仅有 FullGC)。
特殊情况
特殊情况咋办?例如对象比较大的情况。新对象进Eden,空间够就放,不够就Minor GC。GC后存活对象进Survivor,空间够就放,Age加1;Age超15进老年代。Survivor放不下怎么办?直接申请进老年代。老年代空间够就放,不够就触发Full GC(全堆回收),清年轻代、老年代、方法区。Full GC后还不够,就抛OOM(内存溢出)。
Minor GC和Full GC区别?Minor GC只管年轻代,用复制算法,快。Full GC扫全堆,太慢,耗时可能是Minor GC的十倍以上。GC都触发STW(全局停顿),Full GC多的话系统就卡死,所以优化JVM得尽量减Full GC。还有个Major GC,只管老年代,CMS垃圾收集器才有,容易跟Full GC混淆,细节我在这里就不展开了,想了解的问一下 AI,知道有这回事就行。
为啥分代? 简单两个字:效率!对象大多“朝生夕灭”,方法里创建的用完就没引用,适合在年轻代快清。少数顽强的进老年代,GC范围小了,效率高。年轻代1/3,老年代2/3,复制算法管年轻代快准狠,老年代用别的算法成本低。
总结:对象先进Eden,满触发Minor GC,存活的进S0或S1,Age加1,From和To轮换,超15进老年代。Survivor或老年代放不下,可能跳老年代或Full GC,最糟抛OOM。分代是为性能效率。
分代回收案例
先看案例,项目s03里的HeapObjectSample。代码简单:一个static void testCaseOne()方法,里面有个List存对象,死循环每30毫秒加一个50KB的byte[]对象。因为是死循环,List一直持有引用,对象不停产生,最后堆满抛OOM(内存溢出)。启动参数设-Xms60m -Xmx60m -Xmn10m -XX:SurvivorRatio=8 -XX:+PrintGCDetails,意思是堆初始和最大60M,新生代10M(Eden:S0:S1=8:1:1),打印GC详情。算一下:新生代10M,Eden 8M,S0和S1各1M,老年代50M。
运行程序,控制台刷出一堆GC日志,最后OOM。日志分两块:上面是Minor GC(年轻代回收),下面是Full GC(全堆回收),最后堆空间爆了。堆分配概览显示:新生代最大9216K(约9M),老年代51200K(50M)。为啥新生代不是10M?因为S0和S1轮换用,只一个有数据,实际就是Eden 8M + 一个Survivor 1M = 9216K。
看Minor GC日志,比如[GC (Allocation Failure) 8178K->1002K(9216K), 0.0018061 secs]。啥意思?没前缀是Minor GC,括号里Allocation Failure说明Eden满触发GC。8178K->1002K是年轻代占用从8M降到1M,9216K是年轻代最大值。回收后1M在To区(S0或S1),Eden和From区清空。注意,To区1M快满了,放不下的对象可能直奔老年代,这是特殊情况。
再看堆整体变化,8178K->4928K(60416K),GC前堆占8M,GC后剩4.9M,总共60M。时间0.0018061 secs是GC耗时。往下看Full GC日志,比如[Full GC (Ergonomics) ...],原因是垃圾收集器策略触发全堆回收。日志里有年轻代、老年代、方法区(元空间)的变化。老年代没啥变化,说明没清掉东西。多次Full GC后,还是没空间,Allocation Failure再抛OOM。
重跑程序观察:堆占用从低到高,老年代50M快满时,垃圾收集器出现多次Full GC想清空间,失败后OOM。
不过这里我们用 console 去看日志多而杂,线上用VisualVM看更直观。打开VisualVM,选HeapObjectSample,看Visual GC面板:Eden从空涨满,GC后清零再涨;S0、S1轮换复制,满了就塞老年代;老年代阶梯上升,满后Full GC也救不了,OOM结束。
总结:对象先进Eden,满触发Minor GC,存活的进S0或S1,Age加1。S区满,对象直奔老年代,老年代满触发Full GC,还不行就OOM。日志里Minor GC快,Full GC慢,堆分配看Eden和S区轮换,关键数据是占用变化和耗时。掌握这些,能分析线上问题!
# 方法区
方法区是啥?简单说,就是存字节码文件加载后的静态信息的地方。类加载器读完.class文件,里面的类信息、字段、方法、常量等,都得有个地儿放吧?这就是方法区,存的是字节码里的元数据。它有啥特点?第一,线程共享,所有线程都能访问;第二,物理上分散在内存颗粒里,逻辑上是一整块;第三,数据稳定,基本不被垃圾回收(GC)。
方法区存啥?五类东西:1)类加载器信息;2)类信息,包括字段和方法的元数据;3)常量,放运行时常量池里,来自字节码的常量池;4)即时编译器(JIT)的代码缓存,编译后的中间结果;5)静态变量,JDK 1.6前在方法区,1.6后挪到堆里。
方法区只是JVM规范里的概念,具体实现各家厂商不同。就像宾馆得有防火系统,规范要求有,但放灭火器还是装喷头,随你便。HotSpot VM里,JDK 1.7前叫永久代(PermGen),1.8后改成元空间(Metaspace)。为啥改?永久代在JVM内存里,有上限(-XX:MaxPermSize),类一多就OOM。别的VM(像JRocket)早把方法区放本地内存,HotSpot学人家,JDK 8后也挪到本地内存,叫元空间,空间上限就是物理内存,性能更好。改动背后还有商业考量,Oracle收购BEA后,借鉴JRocket的设计。
元空间咋设置?俩参数:-XX:MetaspaceSize设初始大小,默认12-21M(看平台和JVM版本);-XX:MaxMetaspaceSize设最大值,默认-1(物理内存上限)。类多时,初始值小了会自动调大,还可能触发Full GC,影响性能,设置建议:调整为一个较大的值,减少FulIGC的可能。最大值一般不动,超了抛OOM,报“Metaspace”溢出。
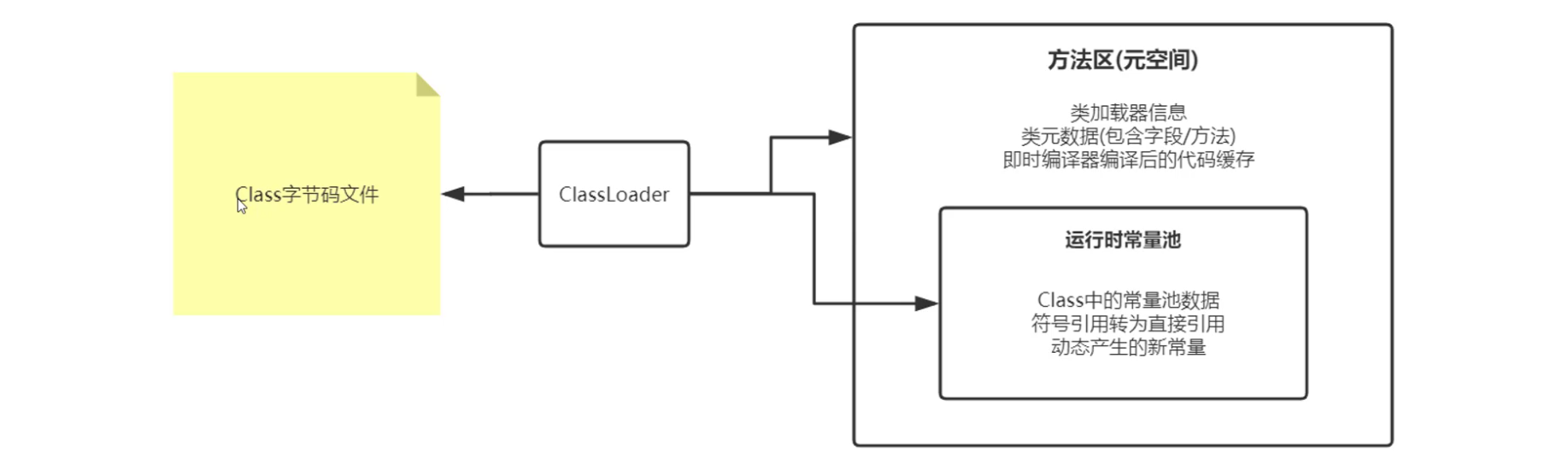
方法区里有个小弟——运行时常量池,干啥的?字节码里的常量池加载后放这儿,比如类名、方法名这些静态常量。还存符号引用转直接引用的指针(内存地址),加上运行时动态生成的新常量(比如Spring用CGLib生成的代理类常量)。图上看:.class文件加载,类信息进方法区,常量池数据进运行时常量池,运行时再加点动态常量。
总结:方法区存字节码元数据,线程共享,稳定少GC。HotSpot里,1.7前是永久代,1.8后是元空间,挪到本地内存,空间大性能好。运行时常量池管常量和指针,数据也稳定。记牢这些,方法区就搞懂了!
# 历史演变
继续聊聊方法区的历史变化,特别是静态变量的存储位置
方法区是JVM规范里的概念,存字节码加载后的类信息、字段、方法、常量等,线程共享。但具体实现没强制要求,不同JVM厂商玩法不同,变化最大的就是方法区。HotSpot VM里,JDK 1.6前叫永久代,1.8后改成元空间,中间有个过渡的1.7。静态变量放哪儿?得看版本。
先看演变。JDK 1.6前,方法区是永久代,在JVM内存里,存类信息、常量、静态变量,连字符串常量池(String Table)也在里头。永久代有上限,类一多就OOM。Oracle收购JRocket(性能超强)后,想学人家把方法区挪到本地内存。JDK 1.7开始去永久代化,静态变量和String Table移到堆里,永久代还在但瘦身了。到了JDK 1.8,永久代彻底淘汰,换成元空间,用本地内存存类信息、字段、方法、常量,静态变量和String Table继续留在堆里。
面试问“静态变量放哪儿”?咱们知道静态变量就是共享的变量,得反问:“哪个版本?”1.6前在永久代,1.7后在堆里。
看清楚:1.6全在永久代(JVM内存),1.7静态变量和String Table进堆,1.8元空间用本地内存,堆里留静态变量和String Table。String Table是哈希表,存运行时字符串常量,别跟字节码常量池或运行时常量池混了。
再讲个易混点:静态变量如果是引用类型,对象实例放哪儿?比如class Person { static Car car = new Car(); }。1.6前,car变量在永久代,new Car()对象在堆里,变量是指针指向堆。1.7后,car变量和对象都在堆里,变量还是指针指向对象。结论:new出来的对象永远在堆里,静态变量只是存位置变了,引用关系不变。
总结:方法区从永久代(JVM内存)变元空间(本地内存),1.6静态变量在永久代,1.7后在堆。记牢版本变化和引用关系