虚拟机5-垃圾收集器
上一个帖子咱们讲完了关于虚拟机它的内部存储区域。下面我们继续来讲内部存储区域它是怎么进行管理的?
垃圾回收(GC)。在Java里,对象的创建方式多种多样,比如用new关键字、反射、克隆,或者反序列化。但对象的销毁,我们不需要操心,为什么呢?这得和C语言比一比。C语言没有垃圾回收器,程序员得手动写析构函数释放内存。这容易出问题:一是忘了释放,导致内存泄漏,慢慢堆积成OOM(内存溢出),这还算好调试;二是释放多次,把不该回收的有效对象干掉了,程序就乱套了,调试难度极大。比如,一个对象释放后,内存又被新对象占用,结果程序逻辑没问题,却因为多次释放把新对象也清了,运行效果完全不可控。这种随机性让问题更难查。
# 什么是垃圾?
Java就不一样了,它引入了垃圾回收器(GC),自动帮我们释放对象。比如年轻代的伊甸园区满了,就会触发Minor GC,清理无用对象。但问题来了,**GC怎么判断对象是垃圾呢?**答案很简单:没引用就是垃圾。
比如对象A持有一个私有字段B,A引用B;如果某天B被设为null,B就失去引用,GC会认为它是垃圾,标记后清理。还有一种情况,一组对象可能整体变垃圾。比如A引用B,B引用C,C引用D,但B和C断开联系,C及后面的链条没引用了,GC会把这整块标记为垃圾,一次性回收。
那GC怎么知道对象没引用呢?这里涉及两种算法。先说“引用计数”,简单粗暴:每个对象有个计数器,有人引用就加1,断开就减1,减到0就回收。但它有个致命问题——处理不了循环引用。循环引用问题:比如A、B、C互相引用,计数器永远不为0,这块内存就泄漏了。这么简单的场景都没有办法处理,所以JVM不用这个。(我们这里开放思维,想象一下,我们能不能开辟一个线程,线程开辟时它自己利用这个线程去创建我们的对象。当我们的线程生命周期结束的时候,我们也随之把刚刚创建的这些对象全部给进行一个 finalize 呢?答案是可以的,但是它的缺点也很明显,就是它没有办法去保证我们的共享变量的使用)
再看“根搜索算法”,也叫可达性分析,这是JVM默认用的。它从GC Root(比如栈帧的局部变量、静态变量、常量池引用等)出发,顺着引用链找,能找到的对象就不回收,找不到的就标记为垃圾。比如有三个对象互相引用,但没GC Root连着,它们就是孤岛,直接回收。
Java靠GC解放程序员,判断垃圾靠“没引用”,核心算法是根搜索。
# 垃圾怎么回收?
JVM垃圾回收的算法主要有三种:标记清除算法、复制交换算法和标记压缩算法。
- 标记清除算法(已被淘汰),最粗暴。先用根搜索标记垃圾对象,然后直接清除,完事。但有个大问题:内存碎片化严重。比如清完后,内存像筛子似的,空隙多但不连续。新来个大对象需要三块连续空间,可惜没地儿放,最后OOM(内存溢出)。因为效率低,JVM现在不用这个。
- 复制交换算法,听着就明白。内存分两块一样大的空间,对象先放一边,放满或触发GC时,把活对象复制到另一边,按顺序整理好,再清空原来那块。比如年轻代的Minor GC,两个Survivor区(S0和S1)就是这么干的——数据从From区复制到To区,清空From区。优点明显:速度快,没碎片,复制就是挨个搬过去,多简单。但缺点也大:空间浪费,得留双倍内存。
- 标记压缩算法,适合老年代。先标记垃圾,然后把活对象压缩挪到一边,整理得整整齐齐,再清垃圾。效果好,没碎片,也不用双倍空间,但效率低,移动对象费CPU,执行时间长。所以老年代Full GC才用它,尽量少触发。
为啥分代用不同算法?年轻代空间小,对象死的快,用复制算法高效又划算;老年代空间大,对象稳定,开双倍内存成本太高,标记压缩就够了,效率低点也能接受。这是性能和成本的平衡。
咱就是说复制交换快但费空间就可以用在年轻代,标记压缩慢但省空间比较适合老年代。
# 垃圾收集器
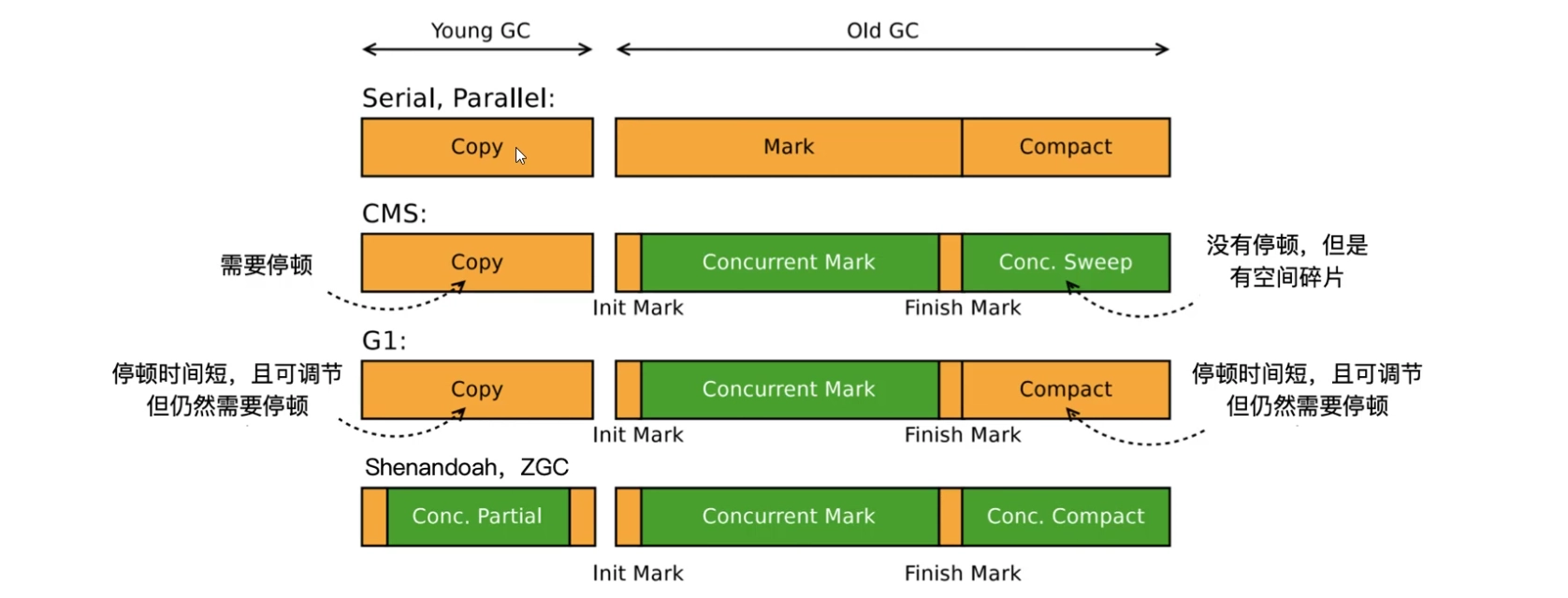
# 分代垃圾收集器
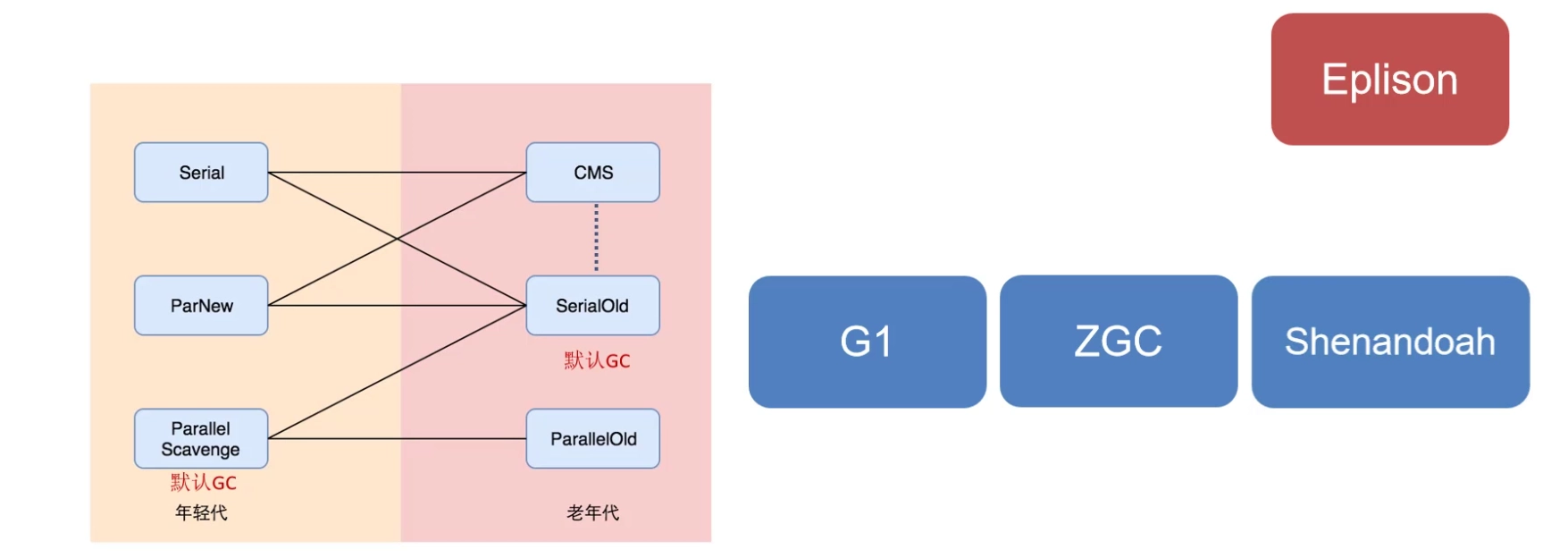
来聊聊Java里的垃圾收集器(GC),咱们已经知道了有三种算法清理内存里的垃圾。下面来看看垃圾收集器的分类,GC分两大类:**分代收集器和不分代收集器。**分代收集器针对堆内存的年轻代和老年代,各有三种,可以搭配使用。比如年轻代用Serial,老年代只能选CMS或Serial Old,反过来也行。JDK 1.8默认是年轻代用Parallel Scavenge(PS),老年代用Serial Old。今天先讲分代收集器,下一节再聊不分代的,像G1、ZGC。
为啥Java搞这么多GC给我们选?不嫌麻烦吗?其实每种GC有自己的特点和适用场景,咱们得搞清楚。
# 年轻代垃圾收集器
- Serial收集器,名字意思是“串行”,最简单。它用单线程回收年轻代的垃圾。流程是这样的:用户线程跑着,伊甸园满了,所有线程停到安全点(比如锁释放后),然后GC单线程开工,用户线程全程暂停,叫“Stop The World”(STW)。GC完,用户线程恢复,满了再停,再清。效率低,因为单线程,太慢了。现在基本淘汰,只适合单核CPU、小内存(几十兆)的场景,大点就不行了。
- Parallel New收集器,简称ParNew,意思是“并行”。它用多线程干活,默认GC线程数跟CPU核数一样,比如4核就4个线程一起清垃圾,效率高,能撑几个G的内存。设计目标是缩短STW时间,所以每次收集很快,但次数多,就像一天吃好几顿,每顿吃一点。适合跟用户高频交互的场景,比如界面操作,STW才10毫秒,用户根本感觉不到。要是停3秒,用户早不耐烦了。
- Parallel Scavenge收集器,简称PS,跟ParNew有点像,但优先考虑吞吐量。吞吐量是GC总时间除以程序运行总时间。PS的特点是STW时间长,但GC次数少,像一天吃两顿,每顿吃撑。JDK 1.8为啥默认用它?因为Java多跑在服务器上,服务器主要是后台计算任务,不怎么跟用户直接交互。STW长点没事,但GC次数少,能让多核CPU专注计算,提高效率。
Serial单线程淘汰了,ParNew多线程适合交互,PS吞吐量优先适合服务器。
# 老年代垃圾收集器
- Serial Old,一看名字就知道是Serial的老年版,JDK 1.8默认的老年代收集器。它用单线程跑标记压缩算法,速度慢,所以得尽量少触发Full GC。简单,但效率低。
- Parallel Old,这是Parallel Scavenge(PS)的老年版。跟PS一样,注重吞吐量,STW(Stop The World)时间长,但GC次数少,用多线程干活。适合服务器后台计算任务,不太在意停顿时间。
- CMS(Concurrent Mark Sweep),名字高级,功能也复杂。它的亮点是并发:用户线程和GC线程一起跑,用户一边产垃圾,GC一边标记清理,STW超短,能撑几十G内存。过程是这样的:先“初始标记”,只扫GC Root的第一层引用,STW很短;然后用户和GC线程并行,标记和清理同时进行;最后“重新标记”,处理异常情况再清扫,STW也不长。
听起来很牛,但CMS有问题。第一,浮动垃圾:并行时,用户新造的垃圾没标记上,漏掉了。第二,标记失败:GC标记一个对象为垃圾,结果用户又引用它,标记错了。这些异常靠重新标记解决,数据量小,STW就短。但致命的是,CMS用标记清除算法,内存碎片多。新对象放不进时,触发Serial Old做全局整理,单线程跑几十G内存,效率低得吓人。一个真实案例使用CMS进行垃圾回收结果碎片太多,Serial Old整理花了一天,程序直接瘫了。
所以CMS虽好,JDK 14后废弃了。它最大的贡献是启发并发思路,催生了G1、ZGC这些新收集器。Serial Old单线程慢,Parallel Old多线程重吞吐量,CMS并发短STW但碎片多。虽然现在咱们都是G1起步了。
| 新生代 (别名) | 老年代 (别名) | JVM 参数 | 备注 |
|---|---|---|---|
| Serial (DefNew) | Serial Old (PSOldGen) | -XX:+UseSerialGC | 单线程,适合小内存场景 |
| Parallel Scavenge (PSYoungGen) | Serial Old (PSOldGen) | -XX:+UseParallelGC | |
| Parallel Scavenge (PSYoungGen) | Parallel Old (ParOldGen) | -XX:+UseParallelOldGC | |
| ParNew (ParNew) | Serial Old (PSOldGen) | -XX:+UseParNewGC | |
| ParNew (ParNew) | CMS + Serial Old (PSOldGen) | -XX:+UseConcMarkSweepGC | |
| G1 | G1 | -XX:+UseG1GC |
- 查默认GC用
java -XX:+PrintCommandLineFlags,看输出就知道。 - 想换组合,直接在命令行加参数,比如
-XX:+UseSerialGC。
# 不分代垃圾收集器
# G1
G1是个成熟的垃圾收集器,从JDK 11开始默认使用。它的最大特点是不明确划分年轻代和老年代,而是把堆内存切成很多小块区域,叫region。每个区域独立管理,逻辑上还是有伊甸园(Eden)、幸存者区(Survivor)和老年代(Old)的分带。所以,G1是物理分区、逻辑分代的收集器,因此被归为不分代收集器。
G1效率高,也更智能。用多线程并发标记和回收,充分发挥多核CPU优势。它的设计理念是追求极短的GC停顿时间,默认单次停顿(STW)最多200毫秒。你可能觉得200毫秒太短,堆内存那么大怎么扫完?G1很聪明,它不指望一次清完所有垃圾,而是优先回收垃圾最多的区域。就像摘草莓,你肯定挑草莓多的地儿摘,单位时间效率更高。G1也是这样,多线程同时处理多块区域,效率拉满。
G1区域有固定规格:1、2、4、8、16、32MB,通过参数设置,最大支持上百GB内存,够大多数公司用了。它的GC策略分三种:
年轻代回收:用复制算法的Minor GC。当伊甸园和幸存者区总和超堆的60%,就触发。对象复制到Survivor区,清空原区域。对象年龄超15或复制量超Survivor区50%,就晋升老年代。
混合GC(Mixed GC):老年代超堆45%时触发,同时回收年轻代和老年代。分四步:初始标记(STW,标记GC Root直接引用的对象)、并发标记(标记引用链,不停顿)、最终标记(STW,修正并发问题)、筛选回收(用标记压缩算法,回收垃圾最多的10%区域)。回收后检查老年代占比,若仍超45%,重复最多8次。
Full GC:8次Mixed GC后老年代仍超45%,就触发单线程Full GC。上百GB内存单线程扫,短则几小时,长则几天,程序基本就崩了。
G1的优势是短停顿、高效率,但Full GC是隐患,得靠调优避免。
# ZGC和Shenandoah
先说啥叫低延迟收集器。简单讲,就是GC停顿(STW)时间小于10毫秒的收集器。以前的GC,比如早期的串行收集器,一GC就全停,用户线程变“黄灯”,体验很差。后来CMS进步了,年轻代复制算法有STW,但老年代回收时只有初始标记和最终标记停顿,其他并行做,绿色时间多了。可CMS用标记清除算法,碎片多,满了我还得单线程Full GC,效率崩盘。到JDK 9的G1,物理不分代,逻辑分代,年轻代复制有STW,标记并发是绿色,但最后压缩整理又停顿,STW还是躲不掉。
为啥老有STW?因为分代设计和对象压缩后指针得变,得停下来改。到了JDK 11和12,ZGC和Shenandoah来了,它们彻底不分代,物理逻辑都不分,用新指针技术解决压缩问题,整个GC过程几乎全是绿色,STW压到10毫秒以内,体验飞起。
先看ZGC。JDK 11推出,实验性,到JDK 14还是如此,只在Oracle JDK用。它分区管理,小区域2MB,中区域32MB,大区域动态但2MB倍数,像分门别类收纳东西,效率高,支持T级内存。核心是“染色指针”,对象移动不用停顿,全程并发,STW几乎没了。
再看Shenandoah。JDK 12出,在Open JDK用,也是实验性。STW也在10毫秒内,但它用固定块大小,不像ZGC动态。它靠“读屏障”和“转发指针”,实现跟ZGC一样的并发效果。两者的区别是底层技术,目的都是不STW。
为啥一个在Oracle JDK,一个在Open JDK?这是厂商竞争。ZGC和Shenandoah来自不同团队,Oracle也不知道谁会胜出,就分开试水,让用户反馈决定未来主流。
咱们最后看看低延迟收集器的牛处:一是彻底不分代,二是用指针技术干掉STW。ZGC和Shenandoah是这方向的先锋,未来可期。
最后的最后提个奇葩,Epsilon。它是个“不干活”的收集器,啥也不回收。只适合超短任务,像计算完就退出的小程序,内存不溢就行。工作中基本用不上。
整个垃圾收集器到这里我们就接近尾声了。到最后我再给出一点,关于我们平时工作开发中常用的配置,继续给出一点干货吧。上面都是原理性的内容,我就放在下一个帖子了